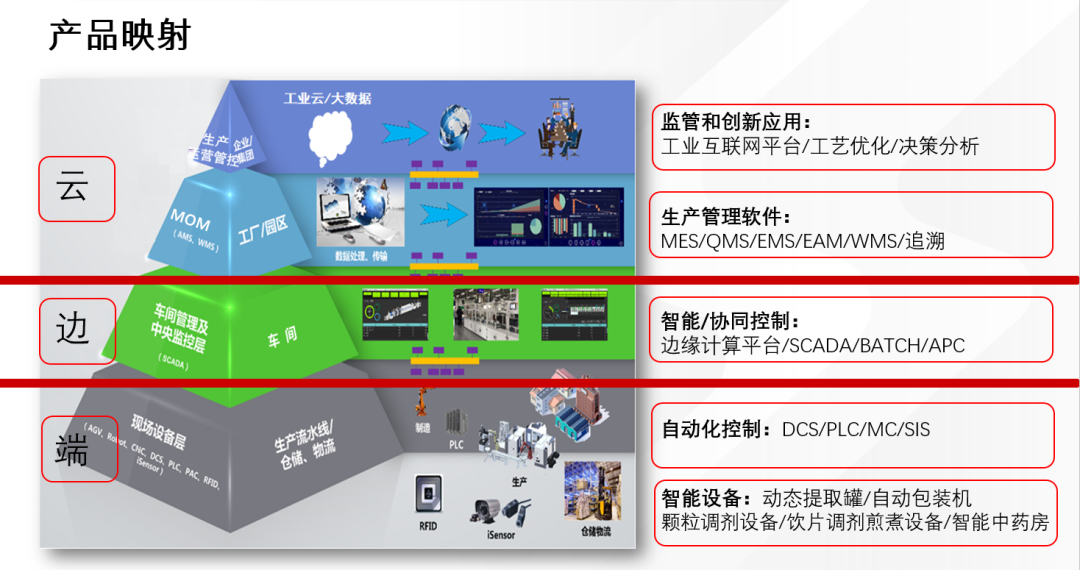
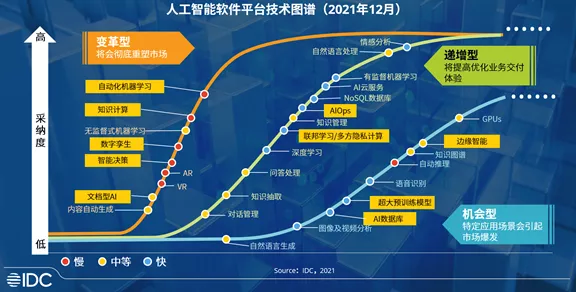
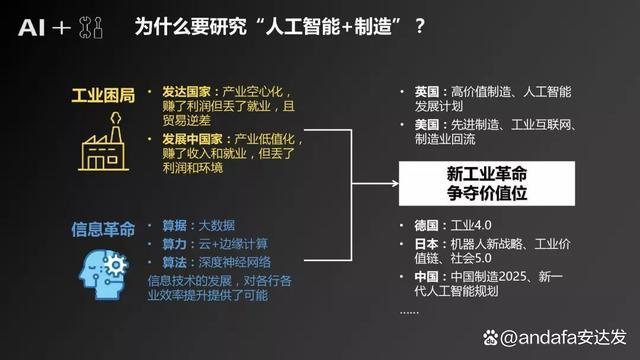
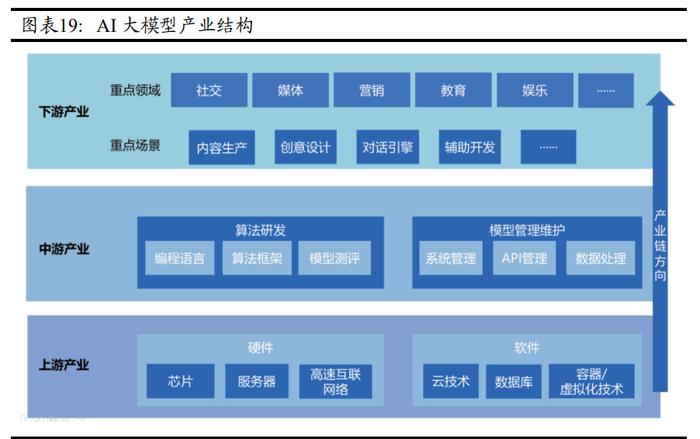
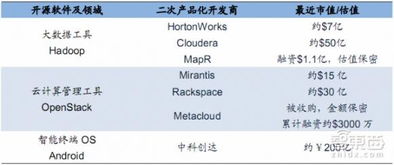
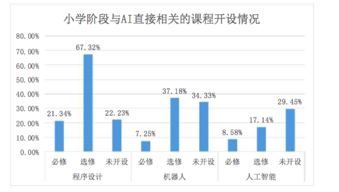
在推進數字中國建設的宏偉藍圖中,數據作為關鍵生產要素,其獨特的稟賦與比較優勢正日益成為驅動創新的核心引擎。尤其在人工智能(AI)基礎軟件開發這一前沿高地,深刻理解并契合我國在數據要素上的稟賦優勢,對于構建自主可控、安全高效的AI技術體系具有戰略意義。
一、數據要素稟賦:數字中國建設的基石與比較優勢
我國擁有世界上規模最大、類型最豐富的數字應用場景和海量數據資源。從電子商務、移動支付到智慧城市、工業互聯網,多樣化的應用場景持續生成結構多元、體量龐大的數據流。這構成了我國發展數字經濟,特別是人工智能產業得天獨厚的“數據要素稟賦”。這種稟賦優勢并非簡單的數據堆砌,而體現在數據的“廣度”(覆蓋經濟社會各領域)、“深度”(蘊含復雜行為與模式)和“鮮度”(實時動態生成)上。它為我們訓練更精準、更適應本土需求的AI模型提供了不可或缺的“燃料”和“試驗場”。
二、人工智能基礎軟件開發:以數據優勢驅動技術突破
人工智能基礎軟件,包括深度學習框架、算法庫、開發平臺及工具鏈等,是AI技術落地與產業賦能的“操作系統”和“工具箱”。其開發高度依賴于高質量、大規模的數據進行模型訓練、算法優化與系統驗證。
我國在AI基礎軟件領域的自主創新,必須充分利用數據稟賦的比較優勢:
- 場景驅動的框架創新: 針對我國在智慧安防、智能交通、金融科技、智能制造等領域的領先應用場景,可定向采集和利用相關領域數據,開發具有場景適應性的專用或優化版深度學習框架與算法組件。這能使基礎軟件更“接地氣”,直接解決產業痛點。
- 數據安全的架構設計: 龐大的數據規模也意味著更高的安全與隱私保護需求。在基礎軟件開發中,應內嵌符合中國法律法規和數據國情的安全計算、聯邦學習、隱私保護等技術架構,確保數據要素在安全可控的前提下流通與利用,這本身也能形成技術特色與壁壘。
- 復雜數據的處理能力鍛造: 我國多源異構(如圖像、視頻、文本、時空數據等)的海量數據,要求基礎軟件具備強大的數據處理、融合與分析能力。以此為導向,可以推動我們在超大規模模型訓練、多模態學習等底層技術上進行攻堅,提升軟件的核心競爭力。
三、契合稟賦,構建發展路徑
要使數據稟賦優勢真正轉化為AI基礎軟件的發展勝勢,需采取系統策略:
- 強化高質量數據供給體系: 在保障安全與隱私的前提下,通過法規標準、技術手段和市場機制,促進數據要素的有序開放、共享與高質量供給,為軟件研發提供優質“原料”。
- 推動“數據-場景-軟件”協同迭代: 鼓勵基礎軟件研發與重點行業應用場景深度融合,形成“真實場景產生數據 -> 數據優化軟件算法 -> 改進軟件賦能新場景”的良性循環,持續打磨軟件性能。
- 加大核心人才與開源生態建設: 培養既懂AI算法又熟悉產業數據的復合型人才,同時積極建設開放、協作的開源社區,吸引全球開發者基于中國的特色數據和應用需求進行創新,共建繁榮生態。
- 參與國際標準與規則制定: 基于我國在數據應用方面的實踐經驗,主動參與乃至引領AI數據治理、模型評估、技術倫理等國際標準與規則的制定,提升在基礎軟件領域的話語權。
數字中國建設非一日之功,人工智能基礎軟件的突破亦是一場持久戰。牢牢把握并充分發揮我國在數據要素稟賦上的比較優勢,將其深度融入從架構設計到算法優化的全鏈條,是走出一條符合國情、自主創新的AI基礎軟件發展道路的關鍵。唯有如此,方能在全球人工智能競爭中夯實基礎,以堅實的基礎軟件能力賦能千行百業,最終推動數字中國宏偉目標的實現。